Data Security Framework
At RunWhen, we prioritize customer data security and have implemented a number of industry best practices in this regard. We believe strongly in secure-by-design, which you will see throughout.
Data Types
Three Types Of Data - We separate the data that is both generated and consumed by RunWhen in to these categories:
Data Type | Highlights |
|---|---|
Source Code From Community Tasks  | This open source code is sent to LLMs, and is a major input for our AI algorithms. Mentioned here for intuition/completeness. |
Enterprise Configuration Data  | Enterprise Configuration Data is marked in red in the user interface. It is considered confidential material, and is anonymized before sending to any LLM (including an enterprise’s own “bring your own endpoint.”) |
Enterprise Automation Output Data  | Automation output follows the same anonymization approach for configuration data as above, and is also considered confidential material. As an extra layer of caution, we also run this text through the industry standard Microsoft Presidio anonymizer, scrubbing any PII-like data along with residual hostnames, account names, IP addresses, UUIDs, any potential keys, etc. that were not configuration data. Our design is inspired by NIST requirements governing the use of moving data center infrastructure manifests from US classified environments to unclassified environments. (This is a common issue for infrastructure vendors supporting their products used in data centers containing classified information.) |
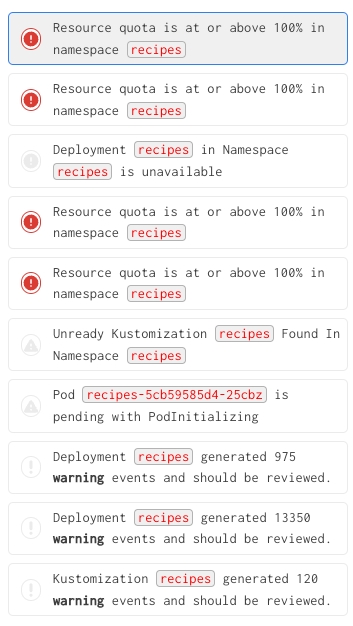
Examples of each of these data types, and notes with respect to their handling, can be found below. A few highlight notes
Source Code From Community Tasks
Source code from open source community tasks is not considered to be enterprise sensitive. We note it here for completeness as this is the input to LLMs that are used in RunWhen's AI algorithms.
The RunWhen Web UI shows clearly which data is sent to LLMs (source code from open source tasks) and data is not (enterprise configuration data).
For context, RunWhen’s Digital Assistant algorithms are not based on LLMs. Instead, they are based primarily on massive scale knowledge graphs. LLMs are used in the construction of these knowledge graphs, but the only data sent back and forth during these steps is the community Task automation source code. Enterprise-specific configuration data is merged later in the pipeline, in workspace-specific versions of the graph that are entirely private. At runtime, the Assistant algorithms also take into account Task and SLI Metadata (see below).

Enterprise Configuration Data
The scope of enterprise configuration data is considered to be the *.yaml files that are stored in the private git repository corresponding to your workspace.
During the process of generating RunWhen configuration files (RunWhen Local Workspace Builder), all metadata used by the RunWhen Platform is available in the Workspace Builder UI for review before any data is uploaded to RunWhen. The configuration data that RunWhen consumes are fields from Kubernetes resource manifests or configuration values from Cloud Assets. It is very rare that these fields contain compliance or security-sensitive data.
Note that most products that do security scanning or cost optimization on cloud accounts and/or Kubernetes accounts are also built around processing this data. It is typically considered to be confidential, sensitive data but it is low-risk with respect to compliance/regulatory requirements in msot organizations. (The data is references to resources such as Kubernetes Namespaces, Deployments or tags used on Cloud VMs.)
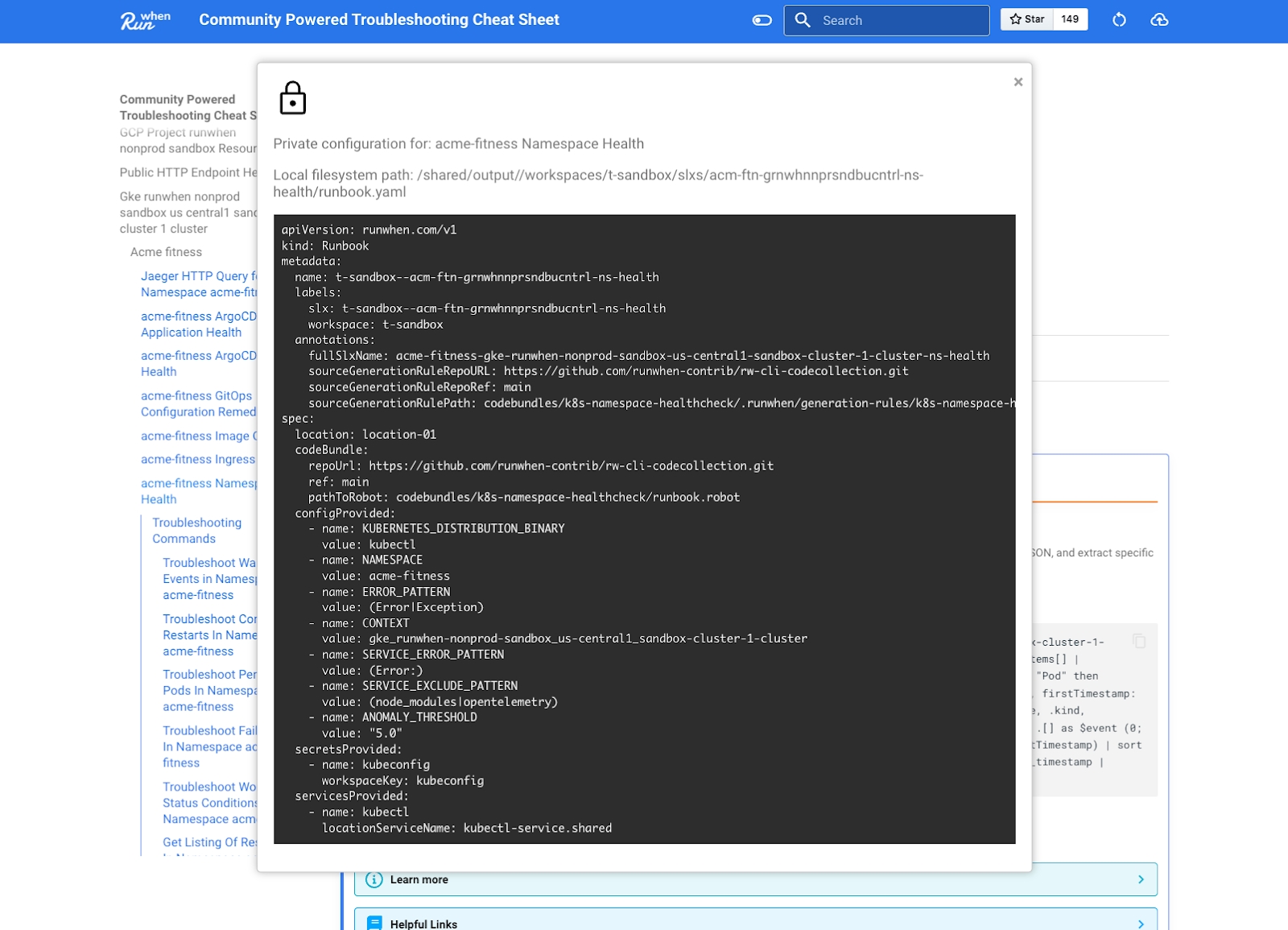
Enterprise Automation Output
When executing automated Tasks, the output is can either be sent from the RunWhen Local in-cluster agent to the RunWhen SaaS platform or (depending on configuration) to local storage. It is then sent through the tier two scrubbing process mentioned above:
Any configuration data found in the output is anonymized
The text is also run through the industry standard Microsoft Presidio anonymizer, scrubbing any PII-like data along with residual hostnames, account names, IP addresses, UUIDs, any potential keys, etc. that were not configuration data.
When sent from the RunWhen Local in-cluster agent, the full output by default it is sent to encrypted GCP buckets via a write-only signed URL upload method. This approach ensures end-to-end encryption, encryption at rest and a high degree of tenant separation by removing any shared database access.
This data may briefly transit the RunWhen Platform when it is rendered in the user interface if a user access it. However, the data is not stored in the platform itself.
Metadata about the output (“Issues” - title, details, severity, next steps) is stored on the RunWhen platform. The content is available for audit at any time via REST APIs (Workspace authentication required) or an inquiry for a large scale export from the RunWhen DevOps team.
Sample full output:
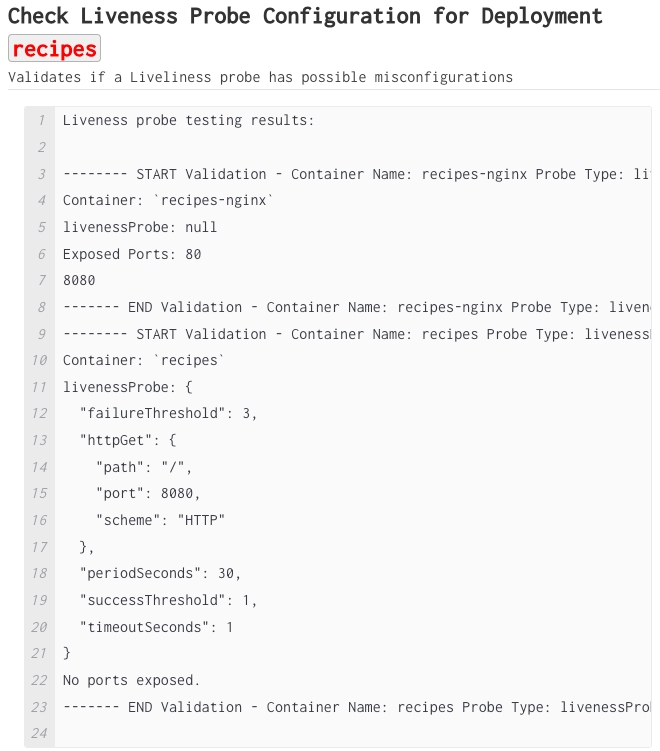
Sample metadata: